
Intel Compilers
Overview
Please refer to the Intel oneAPI toolkit documentation to access the latest and recommended Intel compilers.
The Intel Compilers are highly optimising compilers suitable for the CSF’s Intel processors (all compute node architectures). The compilers include features such as OpenMP and automatic parallelization which allows programmers to easily take advantage of multi-core processors.
Intel Composer XE and Intel Parallel Studio
C (icc), C++ (icpc) and Fortran (ifort)
- 19.1.2 with MKL 2020.0 update 2 (also known as Intel Parallel Studio XE update 1 or 2020.2.108)
- 18.0.3 with MKL 2018.0 update 3 (also known as Intel Composer XE 2018 update 3 or 2018.3.051)
- 17.0.7 with MKL 2017.0 update 4 (also known as Intel Composer XE 2017 update 7 or 2017.7.259)
Programming in Fortran or C/C++ is currently beyond the scope of this webpage.
MKL
The Math Kernel Library (MKL) which is a part of the Intel Compilers contains optimised routines (eg BLAS) that you are encouraged to use for performance gains if not using OpenBLAS (which provides equivalent level 3 BLAS performance on the CSF hardware). Information about MKL.
Restrictions on use
The CSF uses the University license. The Intel compilers are available to any student or member of staff of the University of Manchester for the purpose of the normal business of the University. Such use includes research, personal development and administration and management of the university. The software may not be used for research, consultancy or services leading to commercial exploitation of the software.
Code may be compiled on the login node, but aside from very short test runs (e.g., one minute on fewer than 4 cores), executables must always be run by submitting to the batch system, SGE.
Set up procedure
You will need to load one of the following modulefiles to compile your code and whenever you want to run the executables you compiled. We recommend using the latest version if compiling new code.
Intel Composer XE and Intel Parallel Studio
Note, as of 17.0.7 you only need to load the combined modulefile instead of an individual fortran or c modulefile.
# Provides access to the C, C++ and FORTRAN compilers module load compilers/intel/19.1.2 # Provides icc/ifort 2020.2.254 module load compilers/intel/18.0.3 # Provides icc/ifort 2018.3.222 module load compilers/intel/17.0.7 # Provides icc/ifort 2017.7.259
Running the application – Compiling
We give example firstly of how to compile and then how to run the compiled executable.
Example fortran compilation
Make sure you have loaded the modulefile first (see above).
ifort hello.f90 -o hello # # Generates a binary executable "hello" from source code file "hello.f90"
Example C compilation
Make sure you have loaded the modulefile first (see above).
icc hello.c -o hello # # Generates a binary executable "hello" from source code file "hello.c"...
Example C++ compilation
Make sure you have loaded the modulefile first (see above).
icpc hello.cpp -o hello # # Generates a binary executable "hello" from source code file "hello.cpp"...
Note that is it perfectly acceptable to run the compiler as a batch job. This is recommended if you have a large compilation to perform – one that has a lot of source files and libraries to compile.
Optimizing Flags for CSF Hardware
Note that in general, you will not need to recompile or reinstall any applications, python envs, R packages, conda envs for the AMD Genoa nodes. Things will run perfectly well on the new nodes.
The AMD Genoa hardware provides the avx, avx2 and avx512 vector instructions found in the CSF’s Intel CPUs. So applications are expected to perform at least as well on the new nodes. A full discussion of this hardware is outside of the scope of this page, so please see the AMD documentation if you want more in-depth information.
You may wish to compile code, to be optimized a little more for the AMD nodes. We will be providing more information about this in the next few months, but for now, we have some advice below.
We recommend using the GCC 13.3.0 compiler (or newer) as this supports the AMD znver4 microarchitecture, which enables the AVX-512 extensions.
AMD provide some recommended compiler flags (PDF) to use with various compilers (GNU compiler collection, Intel OneAPI C/C++ and the AMD AOCC compiler.) You will need to use at least anarchitecture flag to enable the AVX-512 extensions available in the Genoa CPUs:
# GNU compilers
-march=znver4 # Code will only run on AMD Genoa and Intel Skylake (or newer)
-march=haswell -mtune=znver4 # Code will run on all CSF3 node types, with some further
# tuning for the AVX-512 extensions found in the AMD and
# Intel Skylake nodes where possible.
# Intel OneAPI compilers - see the Intel OneAPI page elsewhere in our docs
-mavx2 -axCORE-AVX512,CORE-AVX2,AVX # Code will run on all CSF3 node types, with AVX-512
# instruction enabled if supported
# AMD AOCC compilers (not yet installed on the CSF - coming soon)
-march=znver4 # Code will only run on AMD Genoa and Intel Skylake (or newer)
# Note that the above flags can be applied when compiling code on the login nodes.
# An alternative is to login to the AMD nodes, using qrsh, and then compile for
# the "current" node's architecture, using:
-march=native
The above PDF provides further optimization flags you may wish to use in addition to the above architecture flags.
An example of using the common configure command when compiling on CSF3 that we’ve used when installing applications, is:
./configure 'CFLAGS=-march=haswell -mtune=znver4' CPPFLAGS='-march=haswell -mtune=znver4' --prefix=path/to/install/area
The Intel compilers will inform you when it compiles a function it thinks can benefit from optimizations specific to a particular architecture. You’ll see a message of the form:
filename.c(linenum): remark: function_name has been targeted for automatic cpu dispatch
See below for more information on compiling for multiple architectures.
Running your Compiled Code
Once you have compiled your application you will run that as a batch job as normal on the CSF. For example, your compiled application will do some data processing.
You must ensure the same compiler modulefile used to compile your application is loaded when you run your application as a batch job. This is because there are system libraries (and other libraries such as the MKL) that are specific to the compiler version. If you compile your code with Intel compiler 17.0.7, say, then you must run your application with that compiler’s modulefile loaded.
We now recommend loading modulefiles within your jobscript so that you have a full record of how the job was run. See the example jobscript below for how to do this.
Serial Job submission
Ensure that you have the same fortran or C/C++ module loaded that was used to compile the application. The create a batch script similar to:
#!/bin/bash --login #SBATCH -p serial #SBATCH -t 1-0 # Wallclock time limit (e.g., 1-0 is 1 day) # Load the required version module load compilers/intel/17.0.7 # Run your application, found in the current directory ./hello
Submit the job to the batch system using:
sbatch jobscript
where jobscript is replaced with the name of your submission script.
Parallel Job submission
Your code, and thus the resulting executable, must use either OpenMP (for single-node multicore jobs) and/or MPI (for multi-node multicore jobs) in order to run in parallel. Please follow these links to find out how to submit batch jobs of these types to SGE:
Useful Compiler Flags
Please see the relevant man pages. Note that ifort, icc and icpc generally have the same set of flags but will differ for language-specific features.
We suggest a few commonly used flags below but this is by no means an exhaustive list. Please see the man pages.
Optimising and Parallelizing your Code
-O0,-O1,-O2,-O3,-fast(see fortran note): this give you zero (ie no) optimisation (for testing numerics of the code) through to maximum optimisation (which may be processor specific).-vec(which is on by default) vectorizes your code where possible.-openmp,-parallel: for producing hand-coded OpenMP or automatically threaded executables, respectively, to run on smp.pe. Note that-parallelrequires-O2or-O3and that using-O3will enable-opt-matmul. Please consult the man page for full details.-opt-report,-vec-report,-par-report: informs the compiler to produce a report detailing what’s been optimised, vectorized or parallelised. Can increase verbosity and detail by adding optional=Nwhere N is0,1,2… (0to turn off – see man page for range of possible values and what they report). E.g.:-par-report=2.-axand-marchitecture flags: see below for more information on compiling for flags used to optimize code for specific and multiple CPU architectures.
Debugging your Code
Compile your code for use with a debugger.
-g,-traceback,-C: flags for including debug symbols, producing a stacktrace upon runtime errors and for checking array bounds
Profiling your Code
Profiling of loops and function calls can be enabled using the following flags (for icc, icpc and ifort)
-profile-functions -profile-loops=all -profile-loops-report=2
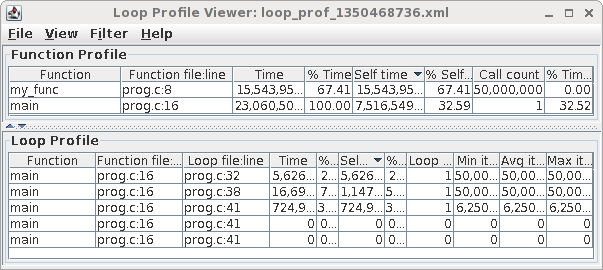
For example, to generate a profiling report of prog.exe and display the results in a graphical tool supplied with the Intel compiler, use the following example
# Ensure you have loaded the required compiler modulefile. Then: # Compile with profiling options. icc -profile-functions -profile-loops=all -profile-loops-report=2 prog.c -o prog.exe # # Or use the 'ifort' fortran compiler # You may also want to add -fno-inline-functions if the profiler # appears not to report calls to some of your functions. # Alternatively add -O0 (which also disables inlining as part of # the optimizations). However, the loop profiler will not work # with -O0. # Copy executable to scratch and run from there cp prog.exe ~/scratch cd ~/scratch # Run your prog.exe code. In this case it is a serial code hence no PE needed. srun -p interactive -t 0-1 ./prog.exe # You'll now have a .xml file (and some .dump files) generated during profiling. # View the xml file in the Intel Java GUI tool. loopprofileviewer.sh loop_prof_1350468736.xml # The number will be different # # Note: if you get an error from Java, try running the tool again. #
You should see something like:
Fortran Static Linking (-lm error)
Compiling FORTRAN code with -static or -fast (which enables -static) may produce an error:
ld: cannot find -lm
This is because linux is moving away from static linking and so the static version of the maths library libm.a is installed in a path not searched by default. Use the following compile line to add the path explicitly:
ifort -fast mycode.f90 -o mycode.exe -L/usr/lib/x86_64-redhat-linux5E/lib64/
Optimizing for Ivybridge, Haswell, Broadwell, Skylake
The CSF compute nodes have been added to the system at different times. Hence the Intel CPU architecture changes as new hardware is made available for us to add to the system. The following architecures are available with different features:
- A significant number of nodes in the CSF use the Intel Ivybridge architecture which supports the AVX instruction set. This allows your code to make use of the 256-bit wide floating-point vector instructions supported by the Intel hardware. The Intel Compiler can auto-vectorise your code in certain circumstances to take advantage of these architectures.
- The Haswell and Broadwell nodes support AVX2 vector instructions. These promote the 128-bit wide integer vector instructions found in AVX hardware to 256-bit wide integer vector instructions.
- The Skylake nodes support AVX512 vector instructions. These promote the 256-bit wide integer vector instructions found in AVX2 hardware to 512-bit wide integer vector instructions. There are additional capabilities including high-accuracy transcendental functions, histogram support, byte, word, double word and quadword scalar data types, masking, and others. See https://colfaxresearch.com/skl-avx512/ for more information.
While a complete discussion of this is beyond the scope of this webpage (and users are encouraged to read the Intel AVX docs), the following compiler flags will allow you to compile a single copy of your application which is optimized for the all of the various Intel architectures:
-msse4.2 -axCORE-AVX512,CORE-AVX2,AVX
Add these flags to your icc or icpc or ifort command. For example:
icc -o my_c_app -msse4.2 -axCORE-AVX512,CORE-AVX2,AVX myapp.c
The -axARCH1,ARCH2,... flag instructs the compiler to generate multiple, processor-specific auto-dispatch code paths if there is a benefit. The code will be compiled in to a single executable. At runtime the executable will select the version of the compiled code suitable for the current architecture where your job is running. For example, if your job is running on a Skylake node then it may be executing the CORE-AVX512 version of particular sections of code if the compiler was able to compile a version using CORE-AVX512 optimizations.
The -mARCH flag sets a baseline architecture optimization for all code for which the compiler could not produce processor-specific auto-dispatch code paths. The sse4.2 architecture will run on all CSF Intel hardware but not all AMD hardware. The older and slower sse2 (lower-case is needed) architecture will run on all CSF hardware.
Note that if you know you will only be running on CSF Intel hardware and not AMD hardware, you may use -xARCH instead of -mARCH. This -x flag compiles code specifically for Intel hardware that will not run on AMD hardware.
The compiler will report which functions have been compiled for both the various -ax architectures with a message such as
../my_solver.c(139): (col. 1) remark: solver_func() has been targeted for automatic cpu dispatch.
The combinations of -x, -ax and -m flags are somewhat complicated and so you are encouraged to read the Intel Compiler manual page (man icc or man ifort).
Intel Compiler Interface to FFTW3 vs Original FFTW3
Please note: the information in this section is repeated on the CSF FFTW Library page.
The Intel Compiler’s Math Kernel Library (MKL) comes with an FFTW3 interface built-in, and FFTW2 interfaces (and FFTW3) can be compiled by you if needed to give yourself a local copy of the Intel library (see below). Hence, if you have source code that uses FFTW functions, you can compile and link your application, without source-code changes, to the MKL libraries and it will use Intel’s built-in version of FFTW3 instead of the FFTW libraries discussed on this page.
Hence there are three methods of using the FFTW if your application makes FFTW function calls:
- Use the original FFTW libraries as described on the CSF FFTW Library page
- Use the Intel Compiler’s built-in FFTW3 (only) implementation in the Intel Math Kernel Library (MKL) [jump there]
- Use the Intel Compiler’s built-in FFTW2 or 3 implementation but compile a local copy of the
libfftw{2,3}XX_intel.alibrary for use in your compilation (some software wants to use this specific library name in the compilation process so it is sometimes easier to compile a local copy then you know you always have it available). [jump there]
You should be able to use either method without changing your source code. Which to use is really a matter of performance and you could compile your app with both versions and do some timing tests to see which is best. The Intel MKL version may run faster on some of the Intel hardware in the CSF but we make no recommendation either way – you must test your own application.
See further below for how to use the original FFTW libraries by loading fftw modulefiles.
All of the examples below assume your C/C++ code contains:
#include <fftw3.h>
Using the Intel MKL Interface to FFTW (without compiling your own local copy)
To compile your application using the Intel built-in FFTW3 library, without referring to a specific libfftw3XX_intel.a library, use the standard Intel compiler MKL flags (note in the example we use the Intel C compiler (icc) but you can also use the Fortran (ifort) or C++ (icpc) compiler with the same flags):
# Load the Intel compiler modulefile
module load compilers/intel/17.0.7
# Compile a serial FFTW application using the MKL built-in FFTW3
icc myfftapp.c -o myfftapp.exe -I${MKLROOT}/include/fftw -mkl=sequential -lm
# Compile an OpenMP (multi-core) application using the MKL built-in FFTW3
icc myfftOMPapp.c -o myfftOMPapp.exe -qopenmp -I${MKLROOT}/include/fftw -mkl -lm
You should now be able to run your application with just the Intel compiler modulefile loaded – you should not use the fftw modulefiles discussed later on this page.
Using the Intel MKL Interface to FFTW (by compiling your own local copy)
If you wish to use the Intel MKL FFTW2 functions, or you wish to have a local copy of Intel’s interface to FFTW3 (e.g. some apps insist on linking against a libfftw{2,3}XX_intel.a library), you can compile the Intel MKL interface yourself so you have a local copy of the libfftw{2,3}XX_intel libraries. Note: If you are using fftw3 functions and want to use the Intel MKL version, you should not need to do the following compilation steps. But it won’t harm if you do:
# Decide on the name and location of a folder where you want to compile a local
# copy of the Intel FFTW3 interface. This might be inside your source tree. For example:
export VBASE=$HOME/myfftapp/fftw3_intel
# Add a sub-directory name for the particular flavour of FFTW3 interface (single precision etc):
# and create that entire directory tree. For example we want the fftw3xf_intel.a library:
mkdir -p $VBASE/fftw3xf/lib
# Load the Intel compiler modulefile for your required version. EG:
module load compilers/intel/17.0.7
# Now, go to the Intel compiler central install area so that you can see
# the FFTW interface files that Intel provides:
pushd $INTELROOT/mkl/interfaces/fftw3xf
# Finally, compiler their interface code but make
# sure it writes to your installation area created above:
make libintel64 compiler=intel install_to=$VBASE/fftw3xf/lib 2>&1 | tee $VBASE/fftw3xf/lib/make-csf.log
# Go back to where you were previously:
popd
# Check we have a library:
ls $VBASE/fftw3xf/lib/*.a
#
# You should see a libfftw3xf_intel.a file listed
# Now, when you compile your source code, you should tell the intel
# compiler where your local copy of the Intel FFTW files are:
icc myfftapp.c -o myfftapp.exe -I${MKLROOT}/include/fftw -L$VBASE/fftw3xf/lib -lfftw3xf_intel
You should now be able to run your application with just the Intel compiler modulefile loaded – you should not use the fftw modulefiles discussed later on this page.
Further info and help
- ITS Applications Intel Fortran Compiler webpage
- Each compiler has an online manual available from the command line:
-
man ifort # for the fortran compiler man icc # for the C/C++ compiler ifort --helpandicc --helpgive similar information- If you require advice on programming matters, for example how to debug or profile a code, or how to use maths libraries, please contact us