
Intel Compilers (icc, icpc, ifort)
Overview
The Intel Compilers are highly optimising compilers and include features such as OpenMP and automatic parallelization which allows programmers to easily take advantage of multi-core processors.
Installed versions:
- Fortran (ifort)
- 12.0.5 with MKL 10.3 Update 5 (also known as Intel Fortran Composer XE 2011 update 5 or 2011.5.220)
- 14.0.3 with MKL 11.1 update 3 (also known as Intel Fortran Composer XE 2013 update 3 or 2013.3.174)
- 15.0.3 with MKL 11.2 update 3 (also known as Intel Fortran Composer XE 2015 update 3 or 2015.3.187)
- C/C++ (icc/icpc)
- 12.0.5 with MKL 10.3 Update 5 (also known as Intel C/C++ Composer XE 2011 update 5 or 2011.5.220)
- 14.0.3 with MKL 11.1 update 3 (also known as Intel C/C++ Composer XE 2013 update 3 or 2013.3.174)
- 15.0.3 with MKL 11.2 update 3 (also known as Intel C/C++ Composer XE 2015 update 3 or 2015.3.187)
Programming in Fortran or C is currently beyond the scope of this webpage. IT Services for Research run training courses which may be of interest.
Restrictions on use
The zCSF uses the University license. The Intel compilers are available to any student or member of staff of the University of Manchester for the purpose of the normal business of the University. Such use includes research, personal development and administration and management of the university. The software may not be used for research, consultancy or services leading to commercial exploitation of the software.
Code may be compiled on the login node, but aside from very short test runs (e.g., one minute on fewer than 4 cores), executables must always be run by submitting to the batch system, SGE.
Set up procedure
You will need to load these modulefiles to compile your code and whenever you want to run the executables you compiled. To access the compilers load the appropriate module (newer versions are preferred if compiling new code):
- Fortran:
module load compilers/intel/15.0.3 # C/C++/Fortran module load compilers/intel/14.0.3 # C/C++/Fortran module load compilers/intel/fortran/12.0.5
- C/C++:
module load compilers/intel/15.0.3 # C/C++/Fortran module load compilers/intel/14.0.3 # C/C++/Fortran module load compilers/intel/c/12.0.5
Note that for version v12.0.5, loading either ifort or icc will make both ifort and icc/icpc available so you really only need to load one of the modulefiles.
The Math Kernel Library (MKL) contains optimised routines (eg BLAS) that you are encourage to use for performance gains.
Running the application
We give example firstly of how to compile and then how to run the compiled executable.
Example fortran compilation
Make sure you have loaded the modulefile first (see above).
ifort hello.f90 -o hello
#
# ...generates a binary executable "hello" from source code
# file "hello.f90"...
#
# ...which can then be run sequn
Example C compilation
Make sure you have loaded the modulefile first (see above).
icc hello.c -o hello
#
# ...generates a binary executable "hello" from source code
# file "hello.c"...
#
Example C++ compilation
Make sure you have loaded the modulefile first (see above).
icpc hello.cpp -o hello
#
# ...generates a binary executable "hello" from source code
# file "hello.cpp"...
#
Useful Compiler Flags
Please see the relevant man pages. Note that ifort, icc and icpc generally have the same set of flags but will differ for language-specific features.
We suggest a few commonly used flags below but this is by no means an exhaustive list. Please see the man pages.
Optimising and Parallelizing your Code
-O0,-O1,-O2,-O3,-fast(see fortran note): this give you zero (ie no) optimisation (for testing numerics of the code) through to maximum optimisation (which may be processor specific).-vec(which is on by default) vectorizes your code where possible.-openmp,-parallel: for producing hand-coded OpenMP or automatically threaded executables, respectively, to run on smp.pe. Note that-parallelrequires-O2or-O3and that using-O3will enable-opt-matmul. Please consult the man page for full details.-opt-report,-vec-report,-par-report: informs the compiler to produce a report detailing what’s been optimised, vectorized or parallelised. Can increase verbosity and detail by adding optional=Nwhere N is0,1,2… (0to turn off – see man page for range of possible values and what they report). E.g.:-par-report=2.
Debugging your Code
Compile your code for use with a debugger.
-g,-traceback,-C: flags for including debug symbols, producing a stacktrace upon runtime errors and for checking array bounds
Profiling your Code
Profiling of loops and function calls can be enabled using the following flags (for both icc and ifort)
-profile-functions -profile-loops=all -profile-loops-report=2
For example, to generate a profiling report of prog.exe and display the results in a graphical tool supplied with the Intel compiler, use the following example:
Log in to your required backend-node (e.g., a GPU node or Xeon Phi node). Run backends on the zrek login node to get a list of commands to do the login. Then:
# Ensure you have loaded the required compiler modulefile. Then: # Compile with profiling options. icc -profile-functions -profile-loops=all -profile-loops-report=2 prog.c -o prog.exe # # Or use the 'ifort' fortran compiler # You may also want to add -fno-inline-functions if the profiler # appears not to report calls to some of your functions. # Alternatively add -O0 (which also disables inlining as part of # the optimizations). However, the loop profiler will not work # with -O0. # # Copy executable to scratch and run from there cp prog.exe ~/scratch cd ~/scratch # Run your prog.exe code. ./prog.exe # You'll now have a .xml file (and some .dump files) generated during profiling. # View the xml file in the Intel Java GUI tool. loopprofileviewer.sh loop_prof_1350468736.xml # The number will be different # # Note: if you get an error from Java, try running the tool again. #
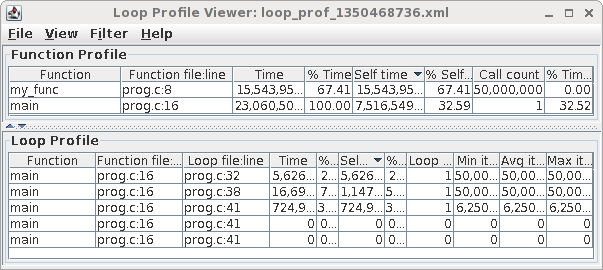
You should see something like:
Fortran Static Linking (-lm error)
Compiling FORTRAN code with -static or -fast (which enables -static) may produce an error:
ld: cannot find -lm
This is because linux is moving away from static linking and so the static version of the maths library libm.a is installed in a path not searched by default. Use the following compile line to add the path explicitly:
ifort -fast mycode.f90 -o mycode.exe -L/usr/lib/x86_64-redhat-linux5E/lib64/
Sandybridge, Ivybridge and Haswell
Zrek backend nodes may use either the Intel Sandybridge architecture or the Intel Ivybridge architecture, both of which supports the AVX instruction set. This allows your code to make use of the 256-bit wide floating-point vector instructions supported by the Intel hardware. The Intel Compiler can auto-vectorise your code in certain circumstances to take advantage of these architectures.
If available Haswell nodes support AVX2 vector instructions. These promote the 128-bit wide integer vector instructions found in AVX hardware to 256-bit wide integer vector instructions.
While a complete discussion of this is beyond the scope of this webpage (and users are encouraged to read the Intel AVX docs), the following compiler flags will allow you to compile code optimized for the Sandy/Ivy Bridge and Haswell architectures:
-xAVXthe compiler may generate processor-specific code for AVX instruction set (Sandybridge / Ivybridge / Haswell architecture). This code will only run on Sandybridge, Ivybridge or Haswell nodes.-axAVXthe compiler will generate multiple, processor-specific auto-dispatch code paths if there is a benefit. This code will execute on Sandybridge, Ivybridge, Haswell nodes and other architectures (Westmere, AMD nodes). The executable may contain multiple versions of sections of code, one of which will be executed depending on whether running on a Sandybridge, Ivybridge or Haswell node or not. The baseline path is determined by the-xflag if present (which sets a baseline causing the executable to work only on Intel architectures) or-mflag (which sets a baseline that runs on Intel and AMD architectures) or a default architecture and optimization level if neither-xor-mare specified. The default baseline settings are usually very conservative – they ensure code runs on very old Intel and AMD architectures and so the performance of the compiled code is not as optimal as it could be. For example, the following flags will set a good baseline (for Intel and AMD nodes in the CSF) and also optimize for newer Intel Sandybridge and Ivybridge nodes in the CSF:-msse2 -axAVX(actually, -msse2 is the default and does not need to be specified). Another option would be to compile with an sse2 baseline and include optional sse4.2 and AVX code paths for optimized execution on Intel hardware (SSE4.2 is supported by our Intel Westmere nodes and is faster than SSE2.) Hence we could also use:-msse2 -axSSE4.2,AVX- For AVX2 hardware (Haswell) add
CORE-AVX2to the-axor-xflags. For example, to compile your code with multiple execution paths to support all possible architectures (AVX2 Haswell, AVX Sandybridge and Ivybridge, SSE4.2 Westmere and a baseline SSE2 that will also work on AMD hardware) use:-msse2 -axSSE4.2,AVX,CORE-AVX2(note that the-msse2must be lower-case).The compiler will report which functions have been compiled for both AVX and non-AVX architectures with a message such as
../my_solver.c(139): (col. 1) remark: solver_func() has been targeted for automatic cpu dispatch.
The combinations of -x, -ax and -m flags are somewhat complicated and so you are encouraged to read the Intel Compiler manual page (man icc or man ifort).
Further info and help
- ITS Applications Intel Fortran Compiler webpage
- Each compiler has an online manual available from the command line:
man ifort
# for the fortran compiler
man icc
# for the C/C++ compiler
ifort --helpandicc --helpgive similar information- Training Courses run by IT Services for Research.
- If you require advice on programming matters, for example how to debug or profile a code, or how to use maths libraries, please email its-ri-team@manchester.ac.uk